Definitie van F-Test-formule
De F-test-formule wordt gebruikt om de statistische test uit te voeren die de persoon die de test uitvoert helpt om te ontdekken dat of de twee populatiesets met de normale verdeling van de datapunten dezelfde standaarddeviatie hebben of niet.
F-Test is elke test die gebruikmaakt van F-distributie. F-waarde is een waarde op de F-verdeling. Verschillende statistische tests genereren een F-waarde. De waarde kan worden gebruikt om te bepalen of de test statistisch significant is. Om twee varianties te vergelijken, moet men de verhouding van de twee varianties berekenen, die is als onder:
F-waarde = grotere steekproefvariantie / kleinere steekproefvariantie = σ 1 2 / σ 2 2
Terwijl F-test in Excel, moeten we de nulhypothesen en alternatieve hypothesen kaderen. Vervolgens moeten we bepalen onder welk significantieniveau de test moet worden uitgevoerd. Vervolgens moeten we de vrijheidsgraden van zowel de teller als de noemer achterhalen. Het zal helpen bij het bepalen van de F-tabelwaarde. De F-waarde die in de tabel wordt gezien, wordt vervolgens vergeleken met de berekende F-waarde om te bepalen of de nulhypothese al dan niet moet worden afgewezen.
Stapsgewijze berekening van een F-toets
Hieronder staan de stappen waarbij de F-Test-formule wordt gebruikt om de nulhypothese te bepalen dat de varianties van twee populaties gelijk zijn:
- Stap 1: Stel eerst de nulhypothese en de alternatieve hypothese in. De nulhypothese gaat ervan uit dat de varianties gelijk zijn. H 0 : σ 1 2 = σ 2 2 . De alternatieve hypothese stelt dat de varianties ongelijk zijn. H 1 : σ 1 2 ≠ σ 2 2 . Hier zijn σ 1 2 en σ 2 2 de symbolen voor varianties.
- Stap 2: Bereken de teststatistiek (F-verdeling). dwz = σ 1 2 / σ 2 2, waarbij wordt aangenomen dat σ 1 2 een grotere steekproefvariantie is en σ 2 2 de kleinere steekproefvariantie is
- Stap 3: Bereken de vrijheidsgraden. Vrijheidsgraad (df 1 ) = n 1 - 1 en Vrijheidsgraad (df 2 ) = n 2 - 1 waarbij n 1 en n 2 de steekproefomvang zijn
- Stap 4: Kijk naar de F-waarde in de F-tabel. Voor tweezijdige tests deelt u de alfa door 2 om de juiste kritische waarde te vinden. Zo wordt de F-waarde gevonden, kijkend naar de vrijheidsgraden in de teller en de noemer in de F-tabel. Df 1 wordt in de bovenste rij gelezen. Df 2 wordt in de eerste kolom gelezen.


Opmerking: er zijn verschillende F-tabellen voor verschillende significantieniveaus. Hierboven staat de F-tabel voor alpha = .050.
- Stap 5: Vergelijk de F-statistiek verkregen in stap 2 met de kritische waarde verkregen in stap 4. Als de F-statistiek groter is dan de kritische waarde op het vereiste significantieniveau, verwerpen we de nulhypothese. Als de F-statistiek verkregen in stap 2 kleiner is dan de kritische waarde op het vereiste significantieniveau, kunnen we de nulhypothese niet verwerpen.
Voorbeelden
Voorbeeld 1
Een statisticus voerde een F-Test uit. Hij kreeg de F-statistiek als 2,38. De door hem verkregen vrijheidsgraden waren 8 en 3. Zoek de F-waarde uit de F-tabel en bepaal of we de nulhypothese kunnen verwerpen op een significantieniveau van 5% (eenzijdige toets).
Oplossing:
We moeten zoeken naar 8 en 3 vrijheidsgraden in de F-tabel. De kritische F-waarde verkregen uit de tabel is 8.845 . Omdat de F-statistiek (2.38) kleiner is dan de F-tabelwaarde (8.845), kunnen we de nulhypothese niet verwerpen.
Voorbeeld 2
Een verzekeringsmaatschappij verkoopt ziektekostenverzekeringen en motorrijtuigenverzekeringen. Voor deze polissen worden premies betaald door klanten. De CEO van de verzekeringsmaatschappij vraagt zich af of de premies die door een van de verzekeringssegmenten (ziektekostenverzekering en autoverzekering) worden betaald, meer variabel zijn dan in een ander. Over betaalde premies vindt hij de volgende gegevens:

Voer een tweezijdige F-toets uit met een significantieniveau van 10%.
Oplossing:
- Stap 1: nulhypothese H 0 : σ 1 2 = σ 2 2
Alternatieve hypothese H a : σ 1 2 ≠ σ 2 2
- Stap 2: F-statistiek = F-waarde = σ 1 2 / σ 2 2 = 200/50 = 4
- Stap 3: df 1 = n 1 - 1 = 11-1 = 10
df 2 = n 2-1 = 51-1 = 50
- Stap 4: Aangezien het een tweezijdige test is, alfaniveau = 0,10 / 2 = 0,050. De F-waarde uit de F-tabel met vrijheidsgraden als 10 en 50 is 2,026.
- Stap 5: Aangezien F-statistiek (4) meer is dan de verkregen tabelwaarde (2.026), verwerpen we de nulhypothese.
Voorbeeld # 3
De bank heeft een hoofdkantoor in Delhi en een filiaal in Mumbai. Er zijn lange wachtrijen voor klanten bij het ene kantoor, terwijl de wachtrijen van klanten kort zijn bij het andere kantoor. De Operations Manager van de bank vraagt zich af of de klanten bij het ene kantoor meer variabel zijn dan het aantal klanten bij een ander kantoor. Een onderzoek bij klanten wordt door hem uitgevoerd.
De variantie van de klanten van het hoofdkantoor in Delhi is 31, en die voor de vestiging in Mumbai is 20. De steekproefomvang voor het hoofdkantoor in Delhi is 11 en die voor de vestiging in Mumbai is 21. Voer een tweezijdige F-test uit met een niveau van significantie van 10%.
Oplossing:
- Stap 1: nulhypothese H 0 : σ 1 2 = σ 2 2
Alternatieve hypothese H a : σ 1 2 ≠ σ 2 2
- Stap 2: F-statistiek = F-waarde = σ 1 2 / σ 2 2 = 31/20 = 1,55
- Stap 3: df 1 = n 1 - 1 = 11-1 = 10
df 2 = n 2-1 = 21-1 = 20
- Stap 4: Aangezien het een tweezijdige test is, alfaniveau = 0,10 / 2 = 0,05. De F-waarde uit de F-tabel met vrijheidsgraden als 10 en 20 is 2,348.
- Stap 5: Aangezien de F-statistiek (1.55) lager is dan de verkregen tabelwaarde (2.348), kunnen we de nulhypothese niet verwerpen.
Relevantie en toepassingen
De F-Test-formule kan in een groot aantal verschillende omgevingen worden gebruikt. F-Test wordt gebruikt om de hypothese te testen dat de varianties van twee populaties gelijk zijn. Ten tweede wordt het gebruikt voor het testen van de hypothese dat de gemiddelden van bepaalde populaties die normaal verdeeld zijn, met dezelfde standaarddeviatie, gelijk zijn. Ten derde wordt het gebruikt om de hypothese te testen dat een voorgesteld regressiemodel goed bij de gegevens past.
F-Test-formule in Excel (met Excel-sjabloon)
Werknemers in een organisatie krijgen dagloon uitbetaald. De CEO van de organisatie maakt zich zorgen over de variabiliteit in lonen tussen mannen en vrouwen in de organisatie. Hieronder staan de gegevens die zijn genomen uit een steekproef van mannen en vrouwen.

Voer een eenzijdige F-test uit met een significantieniveau van 5%.
Oplossing:
- Stap 1: H 0 : σ 1 2 = σ 2 2 , H 1 : σ 1 2 ≠ σ 2 2
- Stap 2: Klik op het tabblad Gegevens> Gegevensanalyse in Excel.

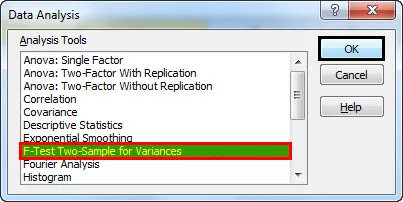
- Stap 3: Het onderstaande venster verschijnt. Selecteer F-Test Two-Sample for Variances en klik vervolgens op OK.
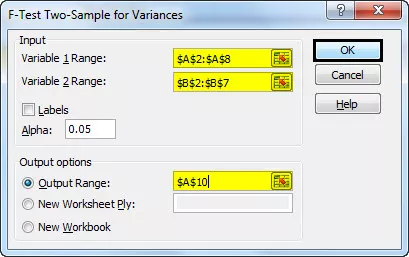
- Stap 4: Klik op het vak Variabele 1 bereik en selecteer het bereik A2: A8. Klik op het vak Variabele 2 bereik en selecteer het bereik B2: B7. Klik op A10 in het uitvoerbereik. Selecteer 0,05 als alfa, aangezien het significantieniveau 5% is. Klik vervolgens op OK.
De waarden voor F-statistiek en F-tabelwaarde worden samen met andere gegevens weergegeven.
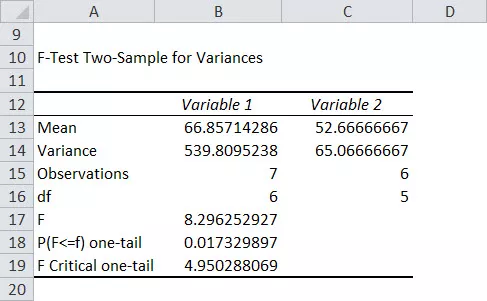
- Stap 4: Uit de bovenstaande tabel kunnen we zien dat de F-statistiek (8,296) groter is dan de F kritische eenzijdige (4,95), dus we zullen de nulhypothese verwerpen.
Opmerking 1: Variantie van variabele 1 moet hoger zijn dan de variantie van variabele 2. Anders zijn berekeningen gemaakt door Excel onjuist. Is dit niet het geval, wissel dan de gegevens om.
Opmerking 2: Als de knop Gegevensanalyse niet beschikbaar is in Excel, ga dan naar Bestand> Opties. Selecteer onder Add-ins Analysis ToolPak en klik op de knop Go. Controleer Analysis Tool Pack en klik op OK.
Opmerking 3: er is een formule in Excel om de F-tabelwaarde te berekenen. De syntaxis is:









